
What’s: Consistent Hashing
A Distributed Hash Table (DHT) is a fundamental component in distributed and scalable systems. Hash Tables rely on a key, a value, and a hash function to map keys to specific locations where their corresponding values are stored.
index = hash_function(key)
For example, consider designing a distributed caching system. With n cache servers, a straightforward hash function might look like key % n. While this approach is simple and widely used, it has two significant limitations:
- Lack of horizontal scalability:
- Adding a new cache server disrupts all existing mappings, breaking the system’s consistency. This issue is particularly problematic when the caching system contains large amounts of data, as updating all mappings during downtime can be highly impractical and challenging to maintain.
- Imbalanced load distribution:
- The function may not distribute data evenly across servers, especially when the data isn’t uniformly distributed. In real-world scenarios, this often leads to some cache servers becoming overloaded (hot spots) while others remain underutilized or nearly empty.
To address these challenges, consistent hashing offers a more effective solution for improving distributed caching systems.
What is Consistent Hashing?
Consistent hashing is a highly effective technique for distributed caching systems and Distributed Hash Tables (DHTs). It enables the distribution of data across a cluster in a way that minimizes reorganization when nodes are added or removed, making it easier to scale the system up or down.
With consistent hashing, when the hash table size changes (e.g., due to the addition of a new cache host), only k/n keys need to be remapped, where k represents the total number of keys and n is the total number of servers. This is a significant improvement compared to systems using a simple hash function like key % n, where all keys need to be remapped whenever the number of servers changes.
Consistent hashing ensures that objects are assigned to the same host whenever possible. When a host is removed, its objects are redistributed among the remaining hosts, and when a new host is added, it takes responsibility for a portion of the data from a few existing hosts without disrupting the rest of the system’s mappings. This balanced redistribution makes consistent hashing an ideal choice for scalable and dynamic distributed systems.
Explanation
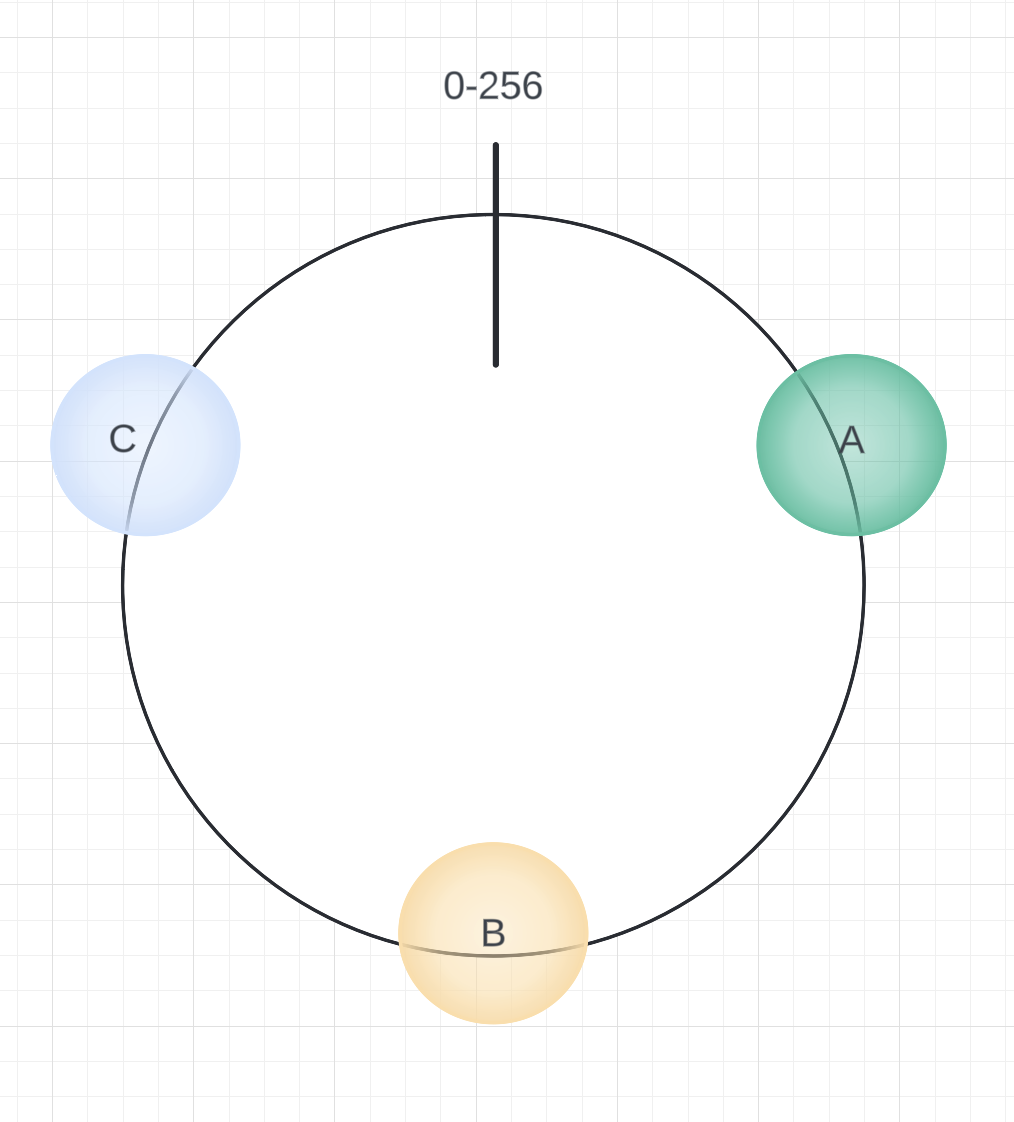
In consistent hashing, keys are mapped to integers using a hash function. For example, if the hash function’s output range is [0,256], the integers are conceptualized as being arranged on a circular ring, where the values wrap around seamlessly.
Here’s how consistent hashing operates:
- Hash the cache servers: Each cache server is hashed to an integer within the defined range and placed on the ring accordingly.
- Mapping keys to servers:
- Each key is hashed to a single integer within the same range.
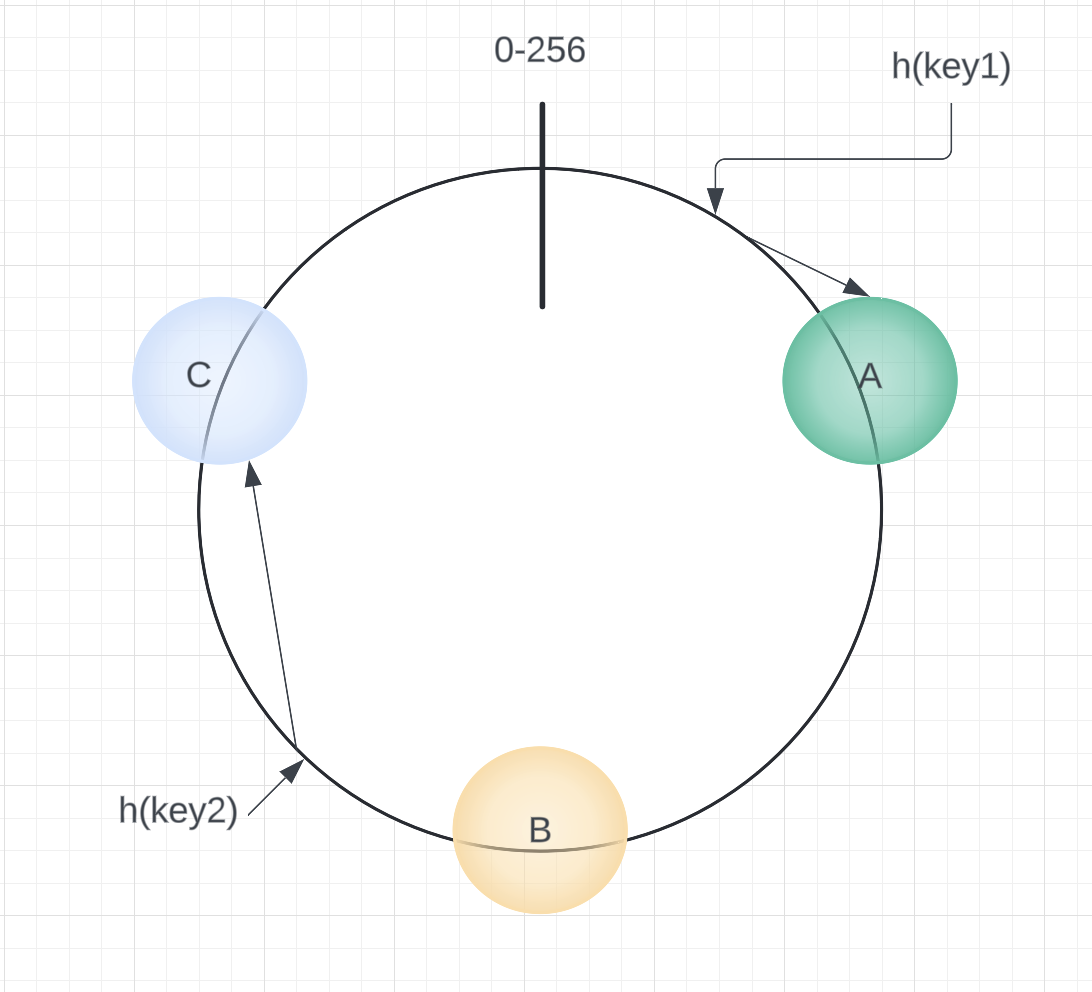
- Starting from the key’s position on the ring, move clockwise until encountering the next cache server.
- The first cache server encountered is responsible for storing the key.
For example, if key1 hashes to a position closest to cache A, it maps to cache A. Similarly, if key2 hashes to a position closer to cache C, it maps to cache C. This process ensures an even and predictable distribution of keys across the servers.
This approach allows the system to handle changes in the number of cache servers efficiently. When servers are added or removed, only the keys that map to the affected portion of the ring need to be reassigned, minimizing disruption.
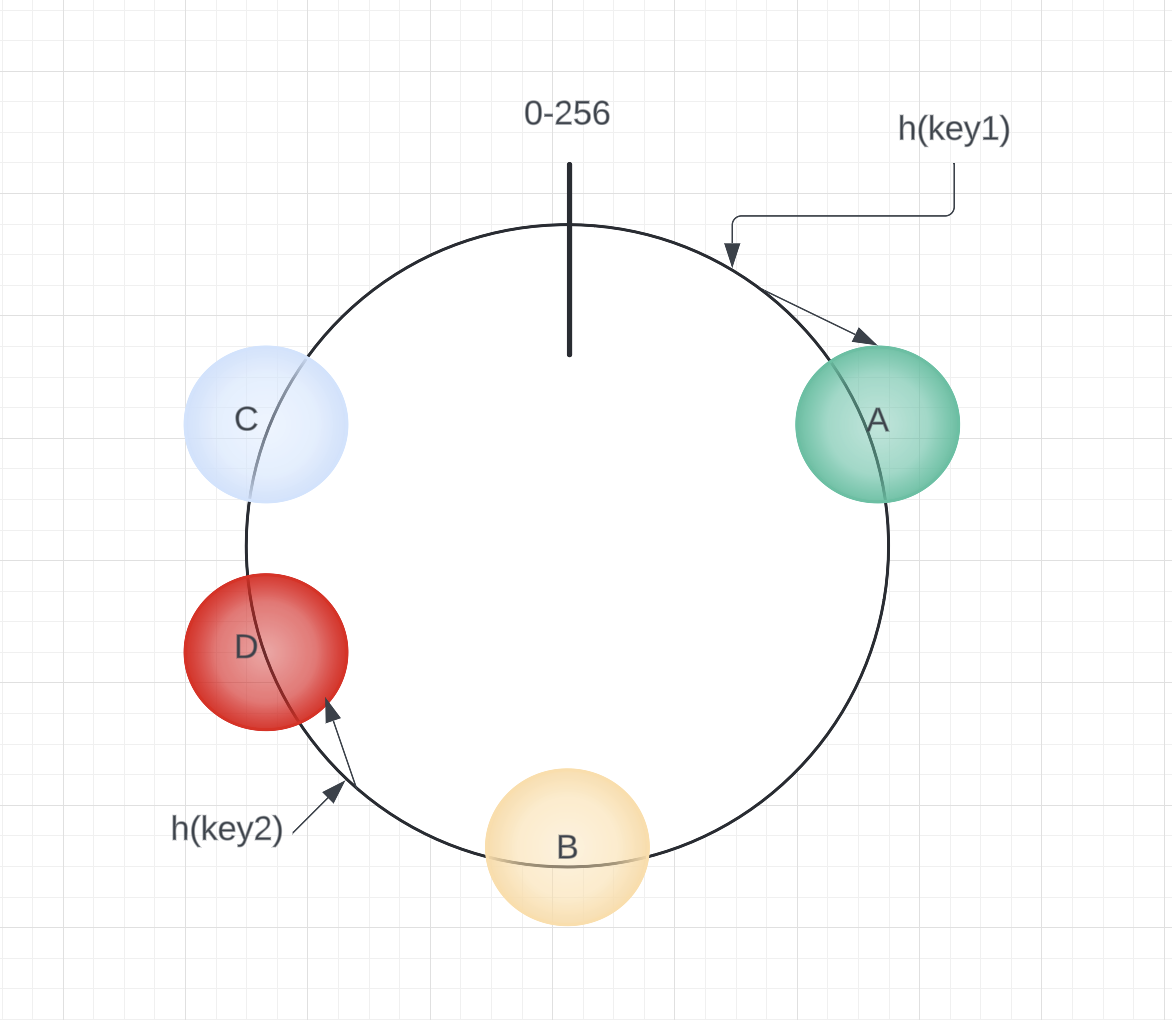
In consistent hashing, when a new server is added, such as server D, the keys originally assigned to server C will be split. Some of these keys will be reallocated to server D, while the rest remain unaffected. This targeted reassignment minimizes disruption across the system.
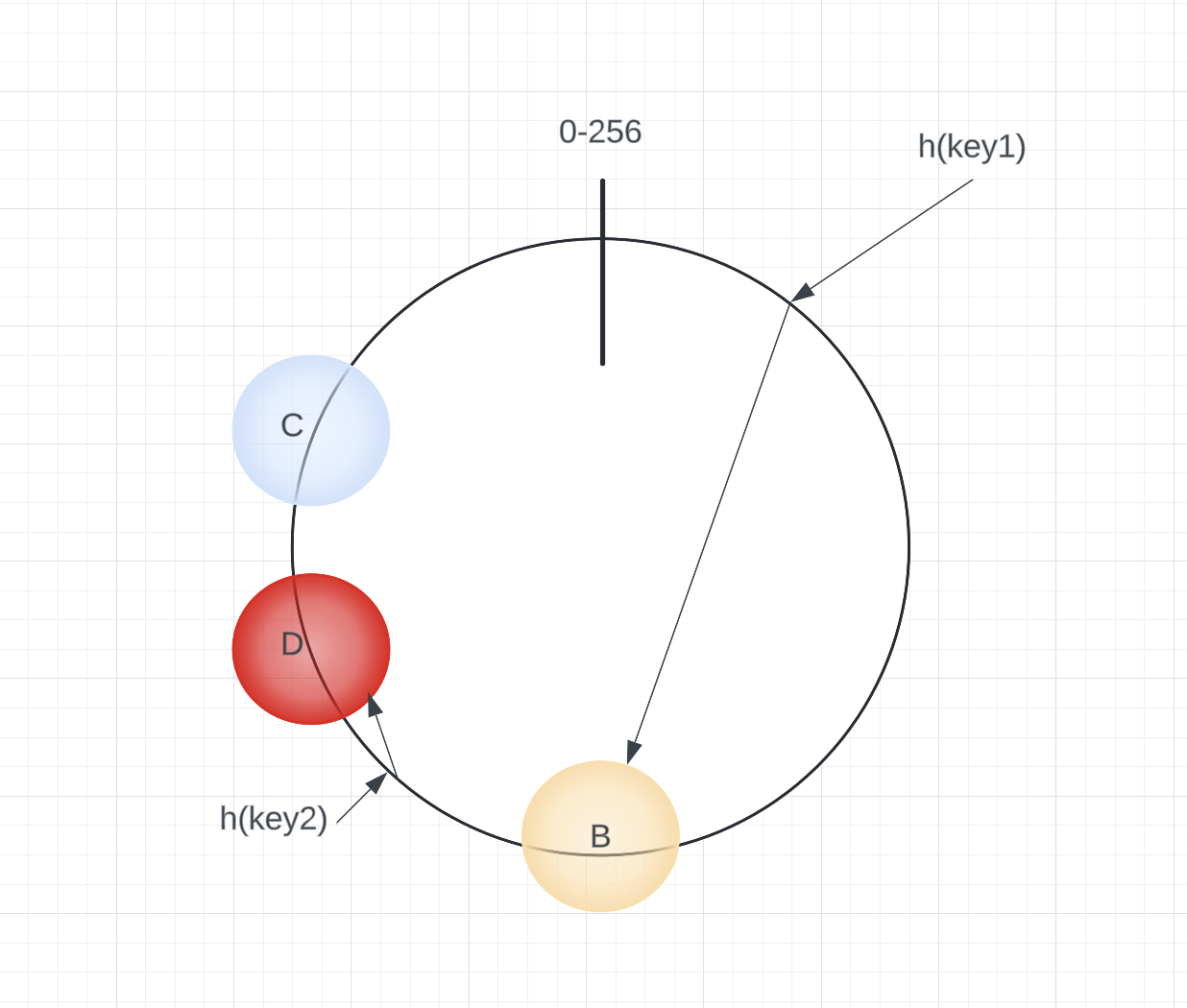
Similarly, if a server is removed or fails, for instance, server A, all keys that were mapped to A will now fall to the next server in a clockwise direction, such as B. Only these specific keys need to be moved, leaving the remaining keys and mappings unchanged.
Load Imbalance
In practice, real-world data tends to be distributed randomly, which can lead to uneven key distribution across servers. This imbalance may cause some servers to handle disproportionately more keys than others.
To resolve this issue, virtual replicas are introduced. Instead of mapping each server to a single point on the ring, each server is mapped to multiple points, known as replicas. By associating each server with multiple segments of the ring, the distribution of keys becomes more uniform.
When the hash function is well-designed and "mixes well," increasing the number of replicas further enhances balance. This ensures that the workload is evenly distributed across all servers, improving the system’s overall efficiency and performance.
Here’s my github golang implementation of consistent hashing - https://github.com/anurakhan/GoMongoDbImageRouter
✉️ Get free system design pdf resource and interview tips weekly
