
Building a URL Shortening Service
Designing a URL shortening service like Bitly involves creating a system that provides compact aliases redirecting users to long URLs.
What’s a URL Shortener?
URL shortening generates concise alternatives to lengthy URLs, allowing users to navigate to the original link when using the alias. These shorter links are especially helpful for platforms with character limits (e.g., social media posts) or when sharing links in presentations or print media.
For instance, consider shortening this URL:
https://www.example.com/learn/courses/designing-a-scalable-url-shortening-service
Through LinkShort, it might become:
http://linkshort.com/abcd12
This shortened link is approximately 1/4th the length of the original. URL shorteners are also useful for link optimization, analytics tracking, and disguising source URLs
Requirements and Objectives
Tip: Always clarify requirements during an interview and ask questions to understand the intended scope.
Functional Requirements:
- Generate a unique and shorter alias for any provided URL.
- Redirect users to the original link when they visit the short URL.
- Support link expiration after a specific duration, either default or user-defined.
- High availability to prevent disruption of redirection services.
- Real-time redirection with minimal latency.
- Ensure shortened links are not guessable or predictable.
Estimations and Constraints
Since this system will be read-heavy, redirection requests are expected to outnumber URL shortening requests by a significant margin. Let’s assume a 100:1 read-to-write ratio.
Traffic Estimates:
- If we anticipate 600M new URLs shortened monthly, we can expect around 60B redirections within the same period.
- Per-second requests:
- Shorten requests: ~230 URLs/s
- Redirect requests: ~23K/s
Storage Estimates:
- Over five years, with 600M new URLs monthly, the system would store 36B URLs:
600M × 12 months × 5 years = 36B- Assuming each stored object requires 600 bytes (metadata included), storage needs are approximately 21.6TB:
36B × 600 bytes = 21.6TB
Bandwidth Estimates:
- Write Operations: With 230 new URLs shortened per second, the incoming data is roughly 138KB/s:
230 × 600 bytes = 138KB/s- Read Operations: With ~23K redirects per second, the outgoing data is approximately 13.8MB/s:
23K × 600 bytes = 13.8MB/s
Memory Estimates:
- To cache frequently accessed (hot) URLs, we assume 20% of the URLs handle 80% of the traffic.
- For 23K requests per second, daily traffic would be ~2B requests:
23K × 3600 seconds × 24 hours = 2B- Caching 20% of these requests requires ~240GB of memory:
0.2 × 2B × 600 bytes = 240GB
Summary of High-Level Estimates:
Defining The APIs
We can use REST APIs. Below are potential definitions for creating and deleting URLs:
createURL(api_dev_key, original_url, custom_alias=None, expire_date=None)
Parameters:
api_dev_key(string): The API developer key of a registered account. This is used for authentication and throttling users based on their allocated quota.original_url(string): The original URL to be shortened.custom_alias(string): Optional custom key for the URL.expire_date(string): Optional expiration date for the shortened URL.
Returns:
- A successful request returns the shortened URL. Otherwise, an error code is returned.
deleteURL(api_dev_key, url_key)
Parameters:
api_dev_key(string): The API developer key of the registered user.url_key(string): Represents the shortened URL to be deleted.
Returns:
- A successful request returns
URL Removed.
Abuse Prevention:To prevent abuse, we can limit the number of URLs a user can create or access within a specified timeframe based on their api_dev_key.
Database
Observations About the Data:
- The system will store billions of records.
- Each record will be small (less than 1KB).
- Records are generally independent, except when tracking which user created a URL.
- The system will be predominantly read-heavy.
Database Schema:
We would need two tables: one for storing URL mappings and another for user data.
What kind of database should we use?For scalability and handling billions of records efficiently, a NoSQL key-value store like DynamoDB or Cassandra is ideal. These databases are optimized for horizontal scaling and avoid complexities like foreign keys. If using NoSQL, we may need a third table to map URLs to users, as foreign keys aren’t natively supported.
System Design
The challenge here is generating a short and unique key for each URL. For example, the shortened URL http://linkshort.com/abcd12 has the unique key abcd12. Below are two possible approaches:
1. Encoding the Actual URL
We can generate a unique hash (e.g., MD5 or SHA256) for the input URL and encode it using Base62 (a-z, A-Z, 0-9). The length of the key can vary:
- Base62 encoding with 6 characters:
62^6 ≈ 56Bunique keys. - Base62 encoding with 8 characters:
62^8 ≈ 218Tunique keys.
For most systems, 6-character keys (56 billion possibilities) are sufficient. To handle duplicates and encoding issues, appending a unique sequence number or user ID can ensure uniqueness.
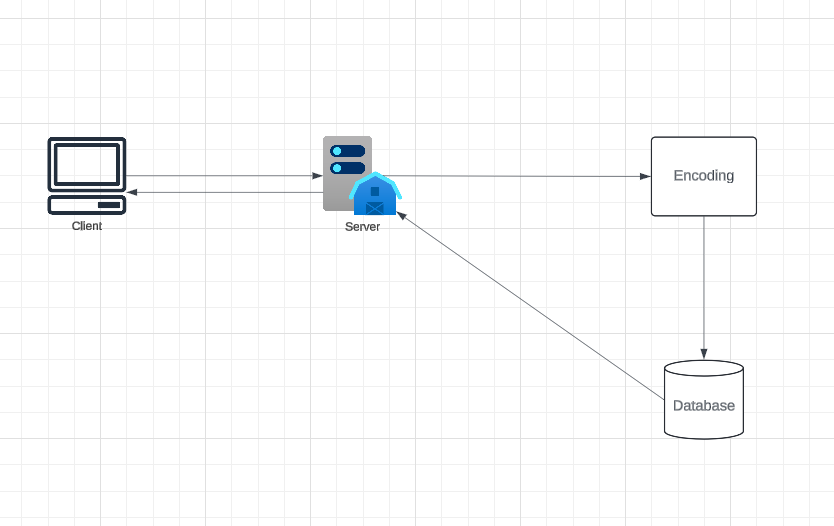
2. Generating Keys Offline
You can pre-generate random keys and store them in a database. When a new short URL is needed, the system retrieves an unused key. The keygen service ensures uniqueness and can scale efficiently by caching keys in memory. Concurrency issues can be managed by marking keys as used immediately upon retrieval with synchronization mechanisms. Further optimization can come from batching and partitioned key pools.
Key Lookup:
- Check the database for the provided short key.
- If found, issue an HTTP 302 redirect with the original URL.
- If not found, return an HTTP 404 status or redirect to the homepage.
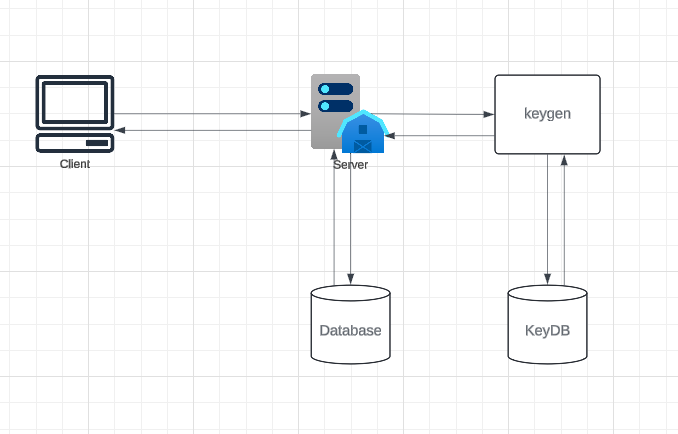
Data Partitioning and Replication
To scale out our database and store information for billions of URLs, we need a partitioning scheme that effectively distributes data across multiple servers.
a. Range-Based Partitioning:
In this approach, URLs are stored in separate partitions based on the first letter of their hash or URL. For example, all URLs starting with ‘A’ could go into one partition, while those starting with ‘B’ go into another. Less frequently used letters can be combined into a single partition.
Challenges:
- Imbalance: Some partitions may become overloaded if certain letters are more common (e.g., URLs starting with ‘E’ might overwhelm their partition).
- Static nature: Adjusting partitions dynamically can be complex.
b. Hash-Based Partitioning:
This method hashes the key (or URL) to determine the partition. The hashing function distributes URLs evenly across partitions (e.g., mapping keys to a range of [1, 256]).
Advantages:
- Random distribution ensures balanced partitions.
Challenges:
- Partition hotspots can still occur but are mitigated using consistent hashing, which dynamically adjusts partitions and minimizes data movement.
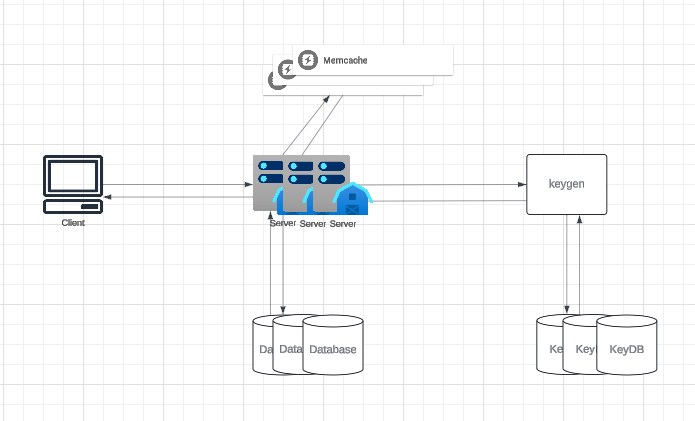
Cache
Caching frequently accessed URLs can significantly improve system performance. An off-the-shelf solution like Memcached can store URL mappings and reduce backend load.
Cache Eviction Policy:
- Least Recently Used (LRU): Discards the least recently accessed entries first.
Cache Replication:
To distribute the load, cache replicas can store redundant data. Updates can propagate as follows:
- On a cache miss, the backend database retrieves the URL and updates the cache.
- Each replica updates itself when new entries are added, ensuring consistency.
This strategy ensures that even with high traffic, the system remains efficient and responsive.
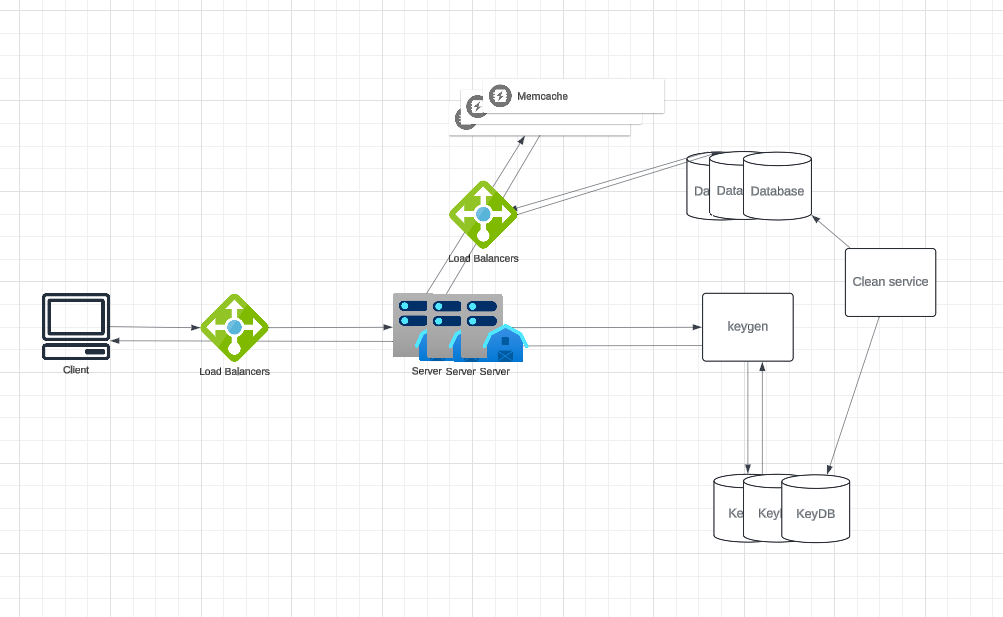
Load Balancer (LB)
A load balancer (LB) can improve system scalability and availability by distributing traffic efficiently. We can incorporate LBs at three key points in our system:
- Between Clients and Application Servers:Distributes incoming traffic from users to multiple application servers. This ensures no single server is overwhelmed.
- Between Application Servers and Database Servers:Balances queries and updates to the database servers, preventing overloading any single database node.
- Between Application Servers and Cache Servers:Manages requests to cache servers, improving response times and avoiding bottlenecks.
Load Balancing Strategies:
- Round Robin: Distributes requests equally among servers. This approach is simple to implement and excludes servers from the rotation if they are unavailable.
- Dynamic Load Balancing: Monitors server load periodically and adjusts traffic accordingly. This prevents overloaded servers from receiving additional requests, improving overall efficiency.
Purging or DB Cleanup
To manage storage efficiently, expired links should be purged periodically. However, care must be taken to minimize the impact on system performance.
- On Access:
- When a user accesses an expired link, delete it immediately and return an error.
- Scheduled Cleanup Service:
- A lightweight cleanup service can run during low traffic periods to remove expired links from storage and cache.
- This service can recycle keys from expired links back into the key pool for reuse.
- Default Expiration:
- Set a default expiration period for all links (e.g., two years). Links can also expire based on user-defined settings.
- Inactive Links:
- Consider removing links that haven’t been accessed for an extended period (e.g., six months). However, given the low cost of modern storage, keeping such links indefinitely may be more practical.
By implementing these strategies, the system can maintain optimal performance while managing storage effectively.
✉️ Get free faang interview cheat sheet and interview tips weekly
