
Building Search System
Requirements
- Assume a social platform has 1.8 billion total users, with 900 million engaging daily.
- On average, the platform processes 450 million posts each day.
- Each post has an average size of 350 bytes.
- Daily search volume reaches approximately 600 million queries.
Our objective is to design a system capable of efficiently storing and querying user posts.
Capacity Estimation and Constraints
Storage Capacity: With 450 million new posts daily, and each post averaging 350 bytes, the daily storage requirement is:
450M * 350 = 157.5GB/day
Storage per second:
157.5GB / 86400 seconds ≈ 1.8MB/second
API
A potential API definition for search might look like this:
search(api_dev_key, search_terms, max_results, page_cursor)
Parameters:
- api_dev_key (string): API developer key for authentication and quota management.
- search_terms (string): The query string containing search keywords.
- max_results (number): Maximum number of posts to return.
- page_cursor (string): Cursor token to retrieve specific pages of the result set.
Returns: (JSON)
A JSON object with details about posts matching the query. Each entry can include user ID, username, post content, post ID, timestamp, like count, and more.
Architecture
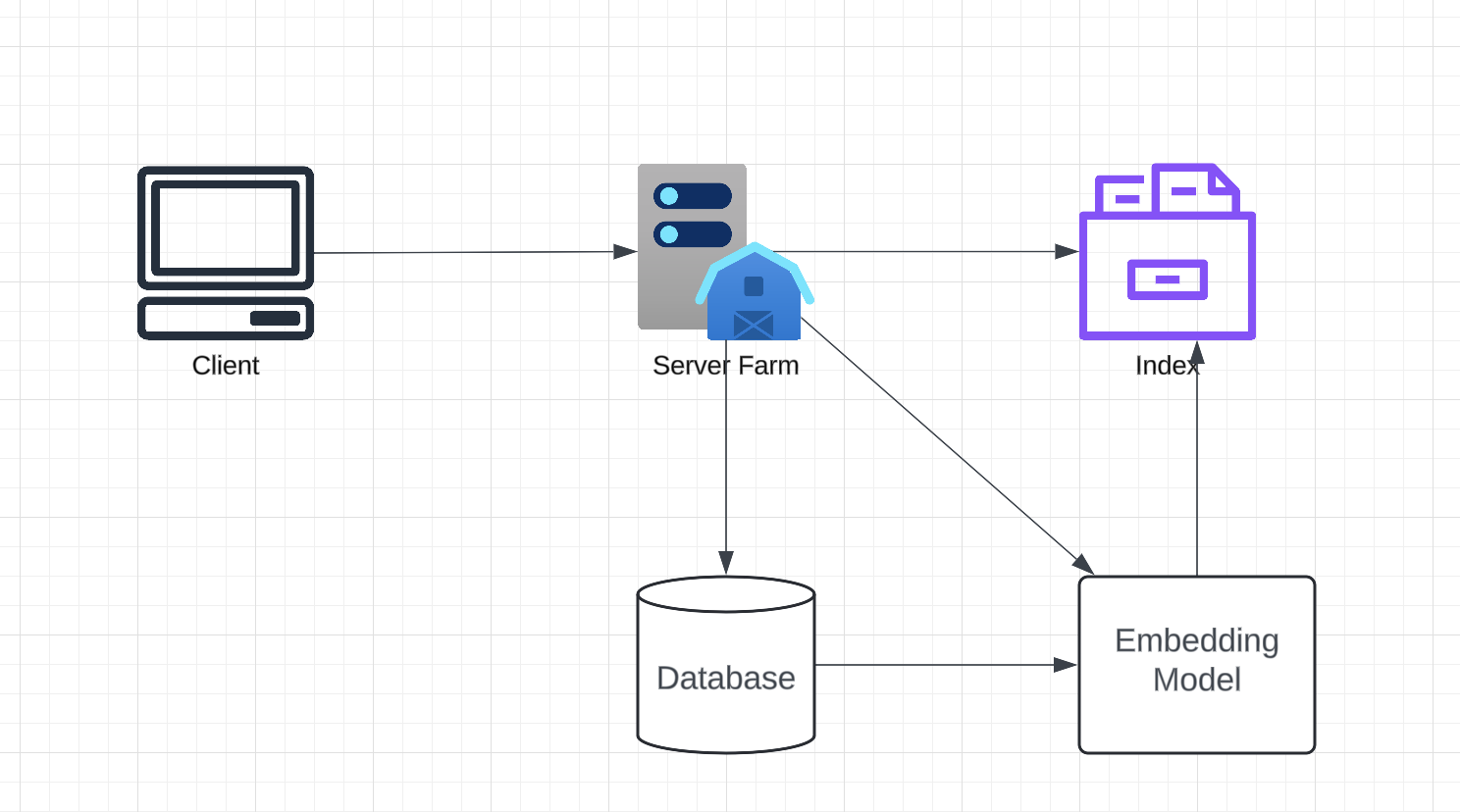
At a high level, the system will store all posts in a database and maintain an index, which will be used for search queries.
- Data Ingestion and Preprocessing
- Collect and preprocess text posts (e.g., filtering, tokenize).
- Store metadata (e.g., post ID, timestamp, user ID).
- Embedding Model
- Train a model to generate embeddings (dense vectors) that represent the semantic meaning of text posts.
- Indexing System
- Use Approximate Nearest Neighbor (ANN) techniques to build scalable indexes for embeddings.
- Aggregator Service
- A query pipeline that transforms user search inputs into embeddings, performs nearest neighbor lookup, ranks, and returns results.
- Storage
- A distributed database for storing raw text posts, metadata, and embeddings.
- Load Balancer and Cache
- Handle high traffic and reduce latency by caching frequent queries and balancing load across servers.
Detailed Component Design
Storage: Storing 157.5GB of new data daily requires an efficient partitioning scheme to distribute data across multiple servers. Planning for five years:
157.5GB * 365 days * 5 years = 287.6TB
To keep storage under 80% utilization, we would need 360TB. Adding redundancy for fault tolerance (e.g., a second copy), total storage grows to 720TB. Assuming modern servers hold up to 5TB each, we would require 144 servers to meet this capacity.
Partitioning could be based on PostID. Using a hash function, the system could map PostID to a specific storage server.
Indexing:
The system allows users to search text posts with high accuracy and speed. A machine learning approach is used for creating embeddings of the text, which represent the semantics of the content. The embeddings are indexed using Approximate Nearest Neighbors (ANN) to allow for efficient similarity searches.
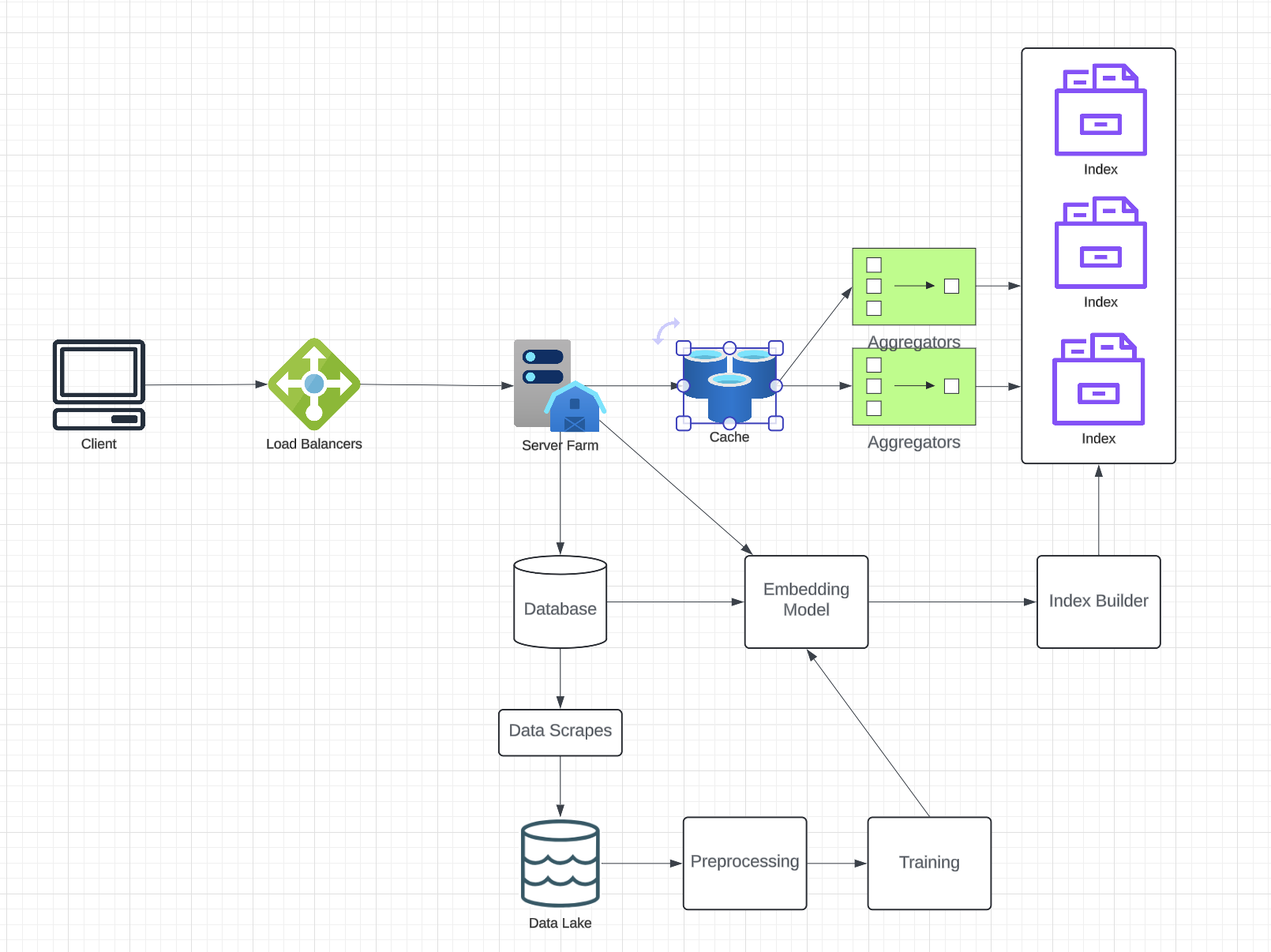
Workflow
- Data Ingestion
- New text posts are ingested via an API.
- Text is preprocessed (e.g., normalization, stop-word removal, tokenization).
- Pass the processed text through the embedding model to generate a vector representation.
- Store embeddings and metadata in a database.
- Training the Embedding Model
- Use a pre-trained transformer model fine-tuned on a dataset of text posts.
- Training involves minimizing a loss function like contrastive loss or triplet loss to ensure semantically similar texts have closer embeddings.
- Building the Index
- Use an ANN library (e.g., FAISS, Annoy, ScaNN) to build an index for the embeddings.
- Indexes are sharded to distribute across nodes and support scaling.
- Periodically rebuild the index to accommodate new posts.
- Query Handling
- Convert user queries into embeddings using the same embedding model.
- Perform a nearest neighbor search in the ANN index to find similar embeddings.
- Retrieve corresponding text posts and metadata from the database.
- Rank results.
- Scaling and Performance Optimization
- Sharding: Distribute data and indexes across multiple nodes based on hash-based sharding.
- Replication: Use replicas for high availability and fault tolerance.
- Caching: Cache frequent query results using Redis or Memcached.
- Batching: Batch multiple queries to reduce index lookup overhead.
- Horizontal Scaling: Add more nodes to handle increased traffic.
- Serving Read Requests
- A distributed search service orchestrates ANN lookups across shards.
- Results are merged and ranked before returning to the user.
For 600 million daily queries, if we assume an ANN (Approximate Nearest Neighbor) index for efficient searches, we must consider index size and distribution:
- Index Entries: Each post corresponds to one index entry. Over five years:
- 450M posts/day * 365 days/year * 5 years = 820 billion entries
- Index Size: Assuming each entry in the index requires 200 bytes:
- 820 billion entries * 200 bytes/entry = 164TB for the index
- Index Partitioning: Distributing the index using hash-based sharding with 256GB of memory:
- 164TB / 256GB ≈ 656 servers
- Query Load: With 600 million daily queries distributed across servers:
- 600M queries/day / 656 servers ≈ 900k queries/server/day
- 900k queries/day / 86400 seconds ≈ 10 queries/second per server
- Replication: If each index shard is replicated for fault tolerance, storage doubles to 512GB per server.
Hash-based partitioning ensures uniform distribution of both storage and query load across servers.
Fault Tolerance
What happens when an index server fails? A secondary replica of each server can take over in the event of a primary server failure. Both primary and secondary servers store identical copies of the index.
What if both primary and secondary servers fail simultaneously? In this case, a new server must be allocated, and the index rebuilt. To rebuild efficiently, a reverse index mapping PostIDs to servers can be maintained. An Index-Builder server holds this mapping in a Hashtable, where the ‘key’ is the server number and the ‘value’ is a HashSet of PostIDs stored on that server. This allows quick retrieval of all PostIDs needed to reconstruct the index. Having a replica of the Index-Builder server ensures additional fault tolerance.
Cache
To handle frequently accessed status objects, a caching layer can be introduced. Using a system like Memcached, hot post objects can be stored in memory. Application servers query the cache before accessing the database. The number of cache servers can be adjusted based on usage patterns. For cache eviction, the Least Recently Used (LRU) policy is suitable for this system.
Load Balancing
Load balancing can be applied at two levels:
- Between Clients and Application Servers: A load balancer distributes incoming requests evenly across application servers. A Round Robin strategy can be used initially, removing failed servers from the rotation automatically.
- Between Application Servers and Backend Servers: A more advanced load balancer can monitor server loads and direct traffic accordingly. This ensures no single server becomes a bottleneck.
✉️ Get free system design pdf resource and interview tips weekly
