
Building a Text Sharing Platform
We’ll create a text-sharing web application, enabling users to store snippets of plain text and access them via unique, random URLs.
What is a Text Sharing Platform?
Such platforms allow users to upload text and generate unique links to access the content. They are frequently used for quickly sharing snippets like code, logs, or notes with others through a simple URL.
System Requirements and Objectives
Our text-sharing service must fulfill the following:
Core Functionalities:
- Users can upload text and receive a unique link for access.
- Only plain text uploads are allowed.
- Uploaded content should expire after a predefined time, with users optionally setting the expiration duration.
- Users may specify a personalized alias for their links.
- Ensure data reliability—uploaded content should not be lost.
- Maintain high availability so users can consistently access their text.
- Minimize latency for real-time text retrieval.
- Generated links should be secure and hard to predict.
Key Design Considerations
While this service shares similarities with a URL shortening system, some unique requirements demand attention:
- Text size limits: To avoid misuse, impose a cap of 8MB per paste.
- Custom URL restrictions: Users may define custom links, but these should have reasonable length restrictions for uniformity.
Estimating Capacity and Constraints
This system is expected to handle far more reads than writes.
Traffic projections:
With an assumption of 800,000 new pastes daily, there would be roughly 4.8 million reads per day.
New pastes per second:
800,000 / (24 × 3600) ≈ 9 pastes/second
Reads per second if 6x more than writes:
4,800,000 / (24 × 3600) ≈ 56 reads/second
Storage estimates:
Average paste size is estimated to be 8KB (as logs or code are typically small).
Daily storage requirement:
800,000 × 8KB = 6.4GB/day
For a decade, the total storage required would be approximately 23TB, assuming no deletions. Allowing for 70% capacity usage, we plan for 33TB.
Unique key storage:
With 2.9 billion pastes over 10 years, a base62 encoding system (A-Z, a-z, 0-9) generating 6-character strings would suffice:
62⁶ ≈ 56 billion unique keys
Storing all keys (assuming 1 byte per character):
2.9 billion × 6 = 17GB, which is negligible relative to 33TB.
Bandwidth estimates:
For uploads: 9 writes/second → 72KB/s
For reads: 56 reads/second → 0.44MB/s
Caching requirements:
Caching the top 20% of accessed pastes requires:
0.2 × 4.8M reads/day × 8KB ≈ 7.7GB.
API
The platform’s core functionalities can be accessed through RESTful APIs. Below are examples:
Create Paste API:
createPaste(api_key, content, custom_alias=None, username=None, title=None, expiration=None)
- Parameters:
api_key(string): A unique key for API quota management.content(string): The text to be stored.custom_alias(string): Optional user-defined alias.username(string): Optional user identifier.title(string): Optional title for the text.expiration(string): Optional expiration time.
- Response: Returns a unique URL or an error code.
Retrieve Paste API:
getPaste(api_key, paste_id)
- Parameters:
paste_id: A unique identifier for the paste.
- Response: Returns the content or an error message.
Delete Paste API:
deletePaste(api_key, paste_id)
- Response: Returns true on success or false on failure.
6. Database Schema
Observations for database design:
- Must store billions of records.
- Metadata (e.g., timestamps, IDs) is small (~50 bytes per record).
- Text content varies from a few KB to several MB.
- Minimal relational dependencies.
- Optimized for heavy read operations.
We would need two tables, one for storing information about the Pastes and the other for users’ data.
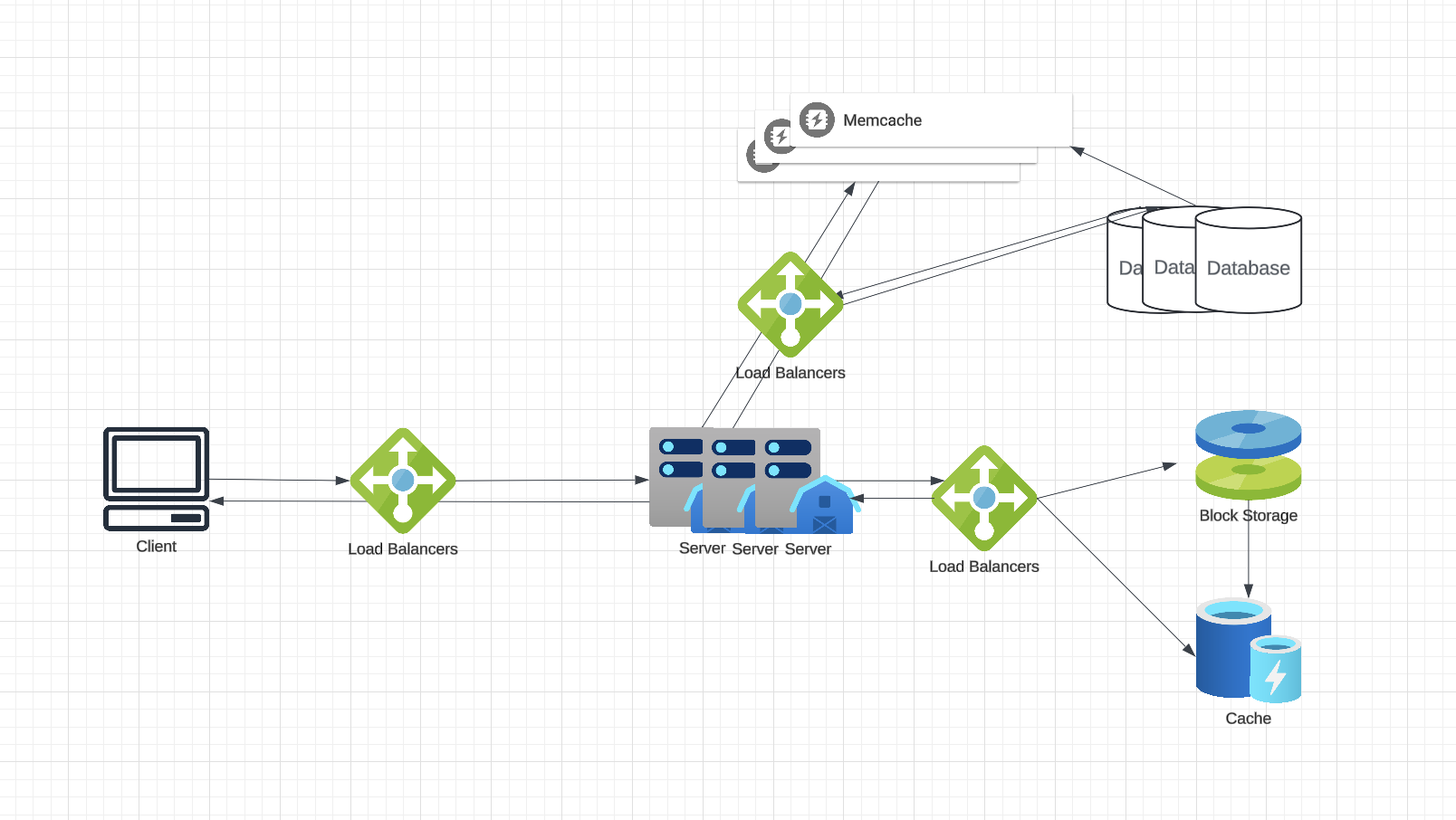
Architecture
At a high level, we need an application layer that will serve all the read and write requests. Application layer will talk to a storage layer to store and retrieve data. We can segregate our storage layer with one database storing metadata related to each paste, users, etc., while the other storing paste contents in some sort of block storage or a database. This division of data will allow us to scale them individually.
Application layer
Our application layer will process all incoming and outgoing requests. The application servers will be talking to the backend data store components to serve the requests.
How to handle a write request? Upon receiving a write request, our application server will insert the data (text content, metadata, etc.) into their respective data stores. After the successful insertion, the server can return the url to the user with key being a UUID or Snowflake ID of the URL Table primary key for that row.
How to handle a paste read request? Upon receiving a read paste request, the application service layer contacts the datastore. The datastore searches for the key, and if it is found, returns the paste’s contents. Otherwise, an error code is returned.
Datastore layer
We can divide our datastore layer into two:
- Metadata database: We can use a relational database like MySQL or a Distributed Key-Value store like Dynamo or Cassandra.
- Blob storage: We can store our contents in a blob storage that could be a distributed file storage or an SQL-like database. Whenever we feel like hitting our full capacity on content storage, we can easily increase it by adding more servers.
✉️ Get free faang interview cheat sheet and interview tips weekly
