
Building Chat App
Requirements
Our messaging platform must meet the following requirements:
- The platform should support direct one-to-one communication between users.
- It must track and display users' online and offline statuses.
- Persistent chat history storage is a fundamental feature.
- The platform should provide a seamless real-time experience with low latency.
- Users must have consistent chat history access across all their devices.
- High availability is prioritized, though some compromises for consistency are acceptable.
Capacity Estimation and Constraints
Let us assume there are 300 million active users daily, with each user sending an average of 50 messages. This leads to 15 billion messages exchanged every day.
Storage Estimation:
Assuming an average message size of 120 bytes:
- Daily storage requirement:
- 15 billion messages × 120 bytes = 1.8 TB/day
- Storage for five years:
- 1.8 TB/day × 365 days/year × 5 years ≈ 3.3 PB
This approximation excludes factors like data compression and replication and does not account for metadata (e.g., timestamps, IDs) or user data storage.
Bandwidth Estimation:
If our platform handles 1.8 TB of data per day:
- Incoming data rate:
- 1.8 TB/day ÷ 86,400 seconds/day ≈ 21 MB/s
- Outgoing data rate (messages sent to recipients):
- 21 MB/s
Total Estimates:
- Total messages: 15 billion per day
- Storage requirements:
- Daily storage: 1.8 TB
- 5-year storage: 3.3 PB
- Data bandwidth:
- Incoming data rate: 21 MB/s
- Outgoing data rate: 21 MB/s
Architecture
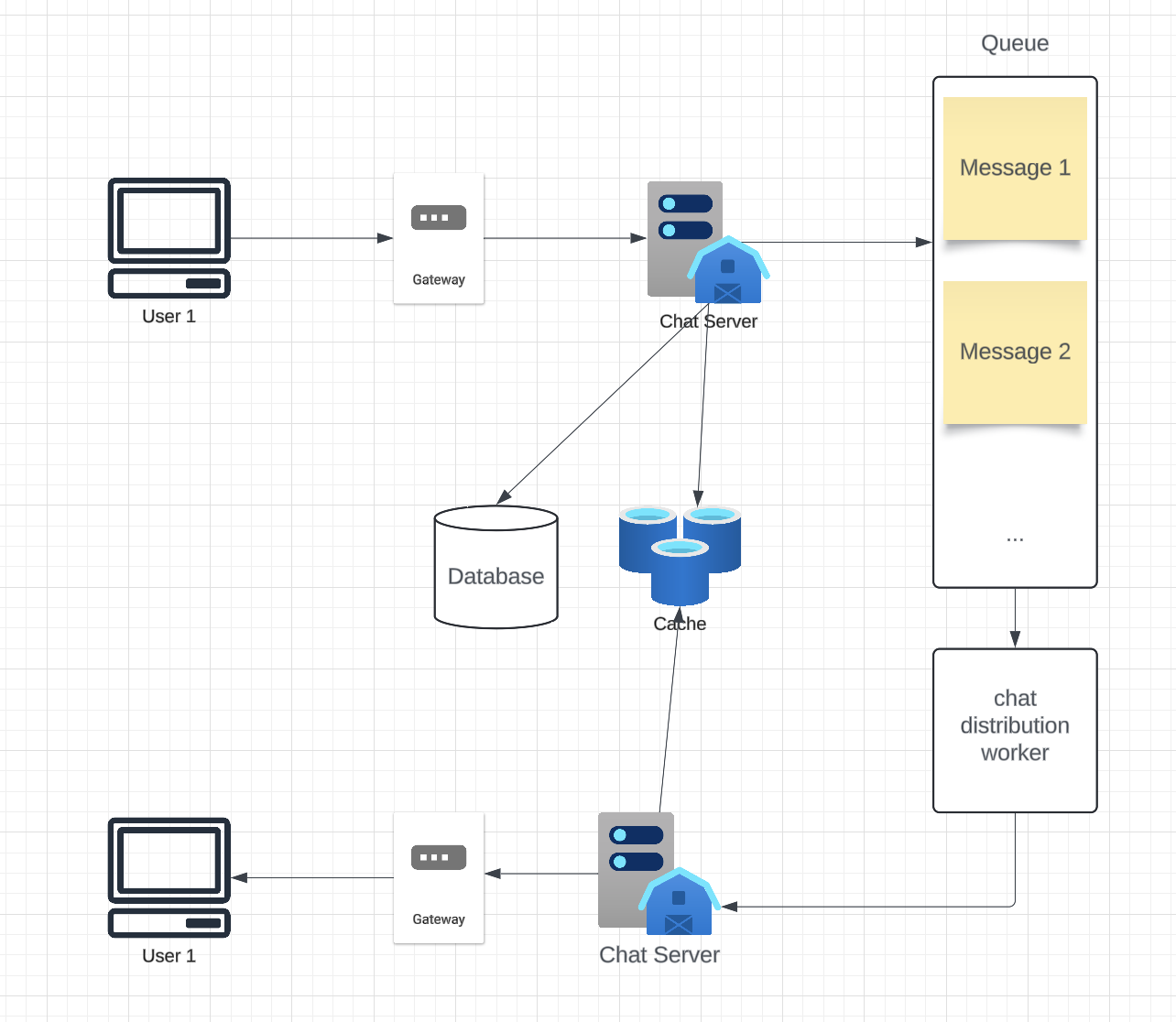
At a high level, we will need couple of components to persist messages, transfer them and maintain connections with users.
- Gateway Service:
- Manages user connections.
- Distributes requests to appropriate services.
- Handles reconnections and maintains session persistence.
- Chat Service:
- Handles message delivery, sequencing, and storage.
- Manages user state (online/offline).
- Message Queue:
- RabbitMQ, Kafka, or Redis Streams for message queuing and delivery reliability.
- Storage Layer:
- Database:
- NoSQL (e.g., MongoDB, DynamoDB) for message storage.
- SQL (e.g., PostgreSQL, MySQL) for relational data like user information.
- Blob Storage:
- For storing multimedia (e.g., AWS S3, Google Cloud Storage).
- Database:
When one user sends a message, it is first routed to the gateway, which then forwards the message to the chat server. The chat server does validation then persists the message in the database, and ads a new item to the messaging queue to be propagated to recipient chat server.
Message Flow Overview
- Sender Client sends a message.
- The Gateway Service handles the connection and forwards the message to the appropriate backend services.
- The Chat Service validates and processes the message.
- The Database stores the message for persistence.
- The Recipient Client receives the message in real-time if online.
Detailed Component Design
Let’s try to build a simple solution first where everything runs on one server. At the high level, our system needs to handle the following use cases:
- Receive incoming messages and deliver outgoing messages.
- Store and retrieve messages from the database.
- Keep a record of which user is online or has gone offline.
Messages Handling
How would we efficiently send/receive messages?
To send messages, a user connects to the server and posts messages for other users. To receive messages, the user has two options:
- Pull model: Users periodically ask the server for new messages.
- Push model: Users keep an open connection with the server, which notifies them of new messages.
The pull model may waste resources as users frequently check for messages and often receive empty responses. The push model is more efficient, as active users maintain open connections, allowing immediate message delivery with minimal latency.
How will clients maintain an open connection with the server?
We can use WebSockets to have an open bi-direction connection between the client and server.
How can the server track open connections?
The server can maintain a hash table where the “key” is the UserID, and the “value” is the connection object. Messages are routed using this mapping. We can use a distributed memcache accessible by all servers to store and query this.
What happens when the server receives a message for an offline user?
For temporarily disconnected users, this would be in the consumer worker server. It will check the status of the recipient connection and if offline will not attempt delivery.
Why Message Queue? Better for scalability. Natural expansion for 1-N chat paradigms.
How many chat servers are required?
Assuming 500 million concurrent users and each server handling 50K connections, we would need 10K servers.
How to know which server holds a user’s connection?
A software load balancer maps UserIDs to specific servers.
Reconnection Detection
- When the user reconnects:
- The Gateway Service establishes a new WebSocket connection.
- The Chat Service updates the user’s status in the State Store to
online.
Message Retrieval
- The Chat Service queries the database for undelivered messages.
- All undelivered messages are fetched, marked as delivered, and sent to the user.
- The messages are delivered via the WebSocket connection.
Managing User Status
To track online/offline status:
- Clients pull statuses of friends upon startup.
- Broadcast status changes with minimal delay.
Design Summary
Clients maintain open connections to send and receive messages. Servers handle routing, Queue handles distribution, storing messages in NoSql, and broadcasting user statuses efficiently with a in-memory StateStore. Clients rely on web sockets for maintaining connection.
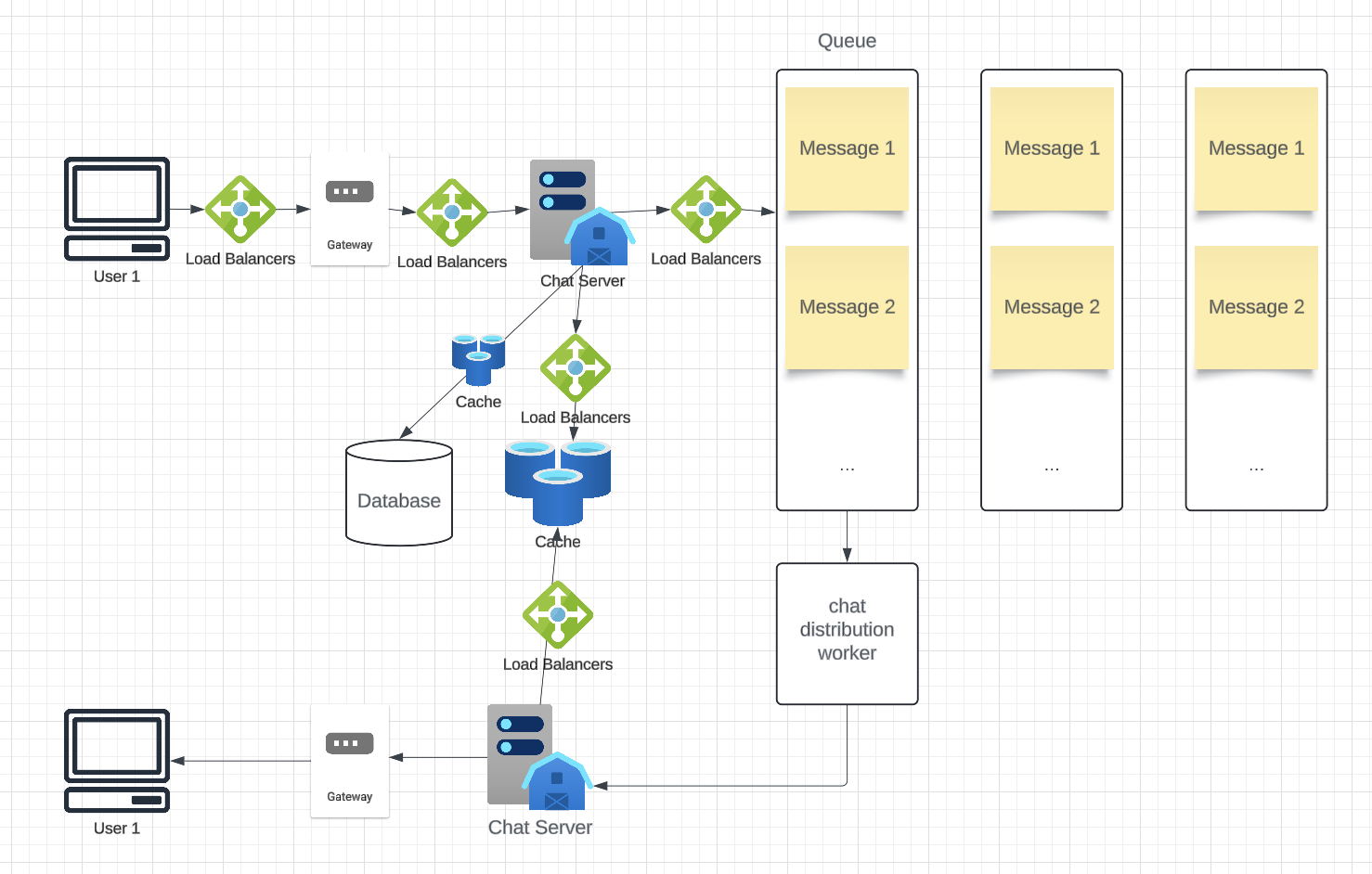
Data Partitioning
Since we will be storing a lot of data (3.3PB for five years), we need to distribute it onto multiple database servers. What would be our partitioning scheme?
Partitioning based on UserID:
We can partition data based on the hash of the UserID, ensuring all messages of a user reside on the same database. Assuming one shard holds 4TB, we would need 3.3PB/4TB ≈ 825 shards. For simplicity, let’s assume 1,000 shards. The shard number can be determined using “hash(UserID) % 1000.”
Initially, multiple shards can reside on one physical server, and as storage demand grows, more servers can be added. Logical partitioning allows flexibility in expanding storage capacity.
Partitioning based on MessageID:
This approach would scatter a user’s messages across shards, making range queries inefficient. Therefore, it’s not recommended.
Message Queue partitioning: Messages might be partitioned based on the recipient ID, ensuring all messages for the same recipient are processed in order.
Cache
We can cache recent messages (e.g., the last 15) in active conversations (e.g., the last 5 visible in the user’s viewport). Since all of a user’s messages are stored on one shard, their cache can also reside on a single machine, improving access efficiency.
Load Balancing
A load balancer in front of chat servers maps each UserID to the server holding their connection. Similarly, cache servers also require load balancers to distribute requests efficiently.
Fault Tolerance and Replication
What happens when a chat server fails?
Chat servers maintain user connections. If a server fails, clients can automatically reconnect. Failover of TCP connections is complex; therefore, automatic reconnection is a simpler and effective solution.
Should we store multiple copies of user messages?
To prevent data loss, we must replicate user messages across multiple servers.
