
Building a Newsfeed
Key Objectives and Requirements of the System
Let’s design a dynamic feed system for a platform with these core requirements:
Functional Requirements:
- The feed will compile posts from connections, followed accounts, and joined groups.
- Users may maintain a substantial network of friends, connections, and subscriptions.
- The feed must support diverse content formats such as text, photos, videos, and shared links.
- The system should seamlessly append new content to the feed for all active users in real time.
- The feed generation should occur with minimal delay, maintaining a user experience latency of under 2 seconds.
- A new post should propagate across relevant feeds within 5 seconds of its creation, assuming the feed request coincides with post generation.
Estimating Capacity and Constraints
Assume a user, on average, follows 250 accounts and has 350 connections.
Traffic Projections:Suppose there are 400M active daily users, each refreshing their feed approximately 4 times daily. This results in 1.6B feed requests per day or around 18,500 requests per second.
Storage Projections:For simplicity, assume each feed retains approximately 600 posts in memory for quick retrieval, with each post averaging 1.2KB in size. Consequently, each user’s feed requires about 720KB. Accommodating 400M users requires approximately 288TB of storage. Given a server’s capacity of 120GB, we’d need around 2,400 servers to host this data in memory.
Defining APIs for the Feed System
We’ll implement REST APIs to handle the feed functionalities. Below is an example of an API to fetch user feeds:
getFeed(api_key, user_id, max_results, filter)
Parameters:
api_key(string): Authentication key for API access. Useful for managing user quotas and security.user_id(integer): Unique ID of the user requesting the feed.max_results(integer): Optional; limits the number of items returned, up to 250 per request.filter(string): Optional; specifies filters like media type or excluding certain categories.
Returns:A JSON object with a list of feed entries containing metadata like post ID, timestamp, media URL, and content.
Structuring the Database
The design involves three main entities: User, Source (e.g., page, group, etc.), and Post. Below are some observations:
- A User can subscribe to sources and connect with other users.
- Posts can originate from both users and sources, with content varying from plain text to multimedia.
- Each Post references its creator through a UserID. For simplicity, let’s assume only users create posts, though, in reality, sources like pages also contribute.
- Posts may optionally reference an associated SourceID, denoting the origin (e.g., a specific group).
Using a relational database, we’d model the following relationships:
- User-Source Relationship: Users follow sources, requiring a table with UserID, SourceID, and Type (indicating whether the source is a user or entity).
- Post-Media Relationship: Posts link to media assets through a separate table. Each record captures PostID and Media metadata, ensuring flexibility for multimedia content.
Table Schemas
Here are the table schemas for the feed system as column names and descriptions:
Users Table
UserID: Unique identifier for each user.UserName: Name of the user.Email: Email address of the user.CreatedAt: Timestamp indicating when the user was created.
Sources Table
SourceID: Unique identifier for each source (e.g., user, page, or group).SourceName: Name of the source.SourceType: Type of source, such as user, page, or group.CreatedAt: Timestamp indicating when the source was created.
Posts Table
PostID: Unique identifier for each post.UserID: Identifier of the user who created the post.SourceID: Identifier of the source (if applicable) where the post was published.Content: Text content of the post.MediaURL: URL to associated media, if any.CreatedAt: Timestamp indicating when the post was created.
UserFollow Table
UserID: Identifier of the user who follows another user or source.FollowedSourceID: Identifier of the user or source being followed.FollowType: Type of follow relationship (e.g., user or source).FollowedAt: Timestamp indicating when the follow relationship was created.
PostMedia Table
MediaID: Unique identifier for each media item.PostID: Identifier of the post associated with the media.MediaType: Type of media (e.g., image, video, or document).MediaURL: URL to the media item.CreatedAt: Timestamp indicating when the media item was created.
High-Level System Design
At a high level, this problem can be divided into two parts:
Feed generation: Newsfeed is generated from the posts (or feed items) of users and entities (pages and groups) that a user follows. Whenever our system receives a request to generate the feed for a user, we will perform the following steps:
- Retrieve IDs of all users and entities that the user follows.
- Retrieve the latest, most popular, and relevant posts for those IDs.
- Rank these posts based on relevance.
- Store this feed in the cache and return top posts (say 20) for rendering.
- On the front end, the user can fetch the next 20 posts from the server and so on.
One thing to notice here is that we generated the feed once and stored it in the cache. What about new incoming posts? We can periodically perform the above steps to rank and add the newer posts to the feed. The user will be notified that there are newer items for fetching.
Feed publishing: Whenever the user loads newsfeed page, they have to request and pull feed items from the server. When they reaches the end of the current feed, they can pull more data from the server. For newer items, either the server can notify the user and then they can pull, or the server can push these new posts.
At a high level, we would need the following components in our Newsfeed service:
- Backend Server: To execute the workflows of storing new posts in the database servers. We would also need some servers to retrieve and push the feed to the end user.
- Metadata database and cache: To store the metadata about Users, Pages, and Groups.
- Posts database and cache: To store metadata about posts and their contents.
- Video and photo storage, and cache: Blob storage, to store all the media included in the posts.
- Newsfeed generation service: To gather and rank all the relevant posts for a user to generate a newsfeed and store it in the cache. This service would also receive live updates and will add these newer feed items to any user’s timeline.
- Feed notification service: To notify the user that there are newer items available for their newsfeed.
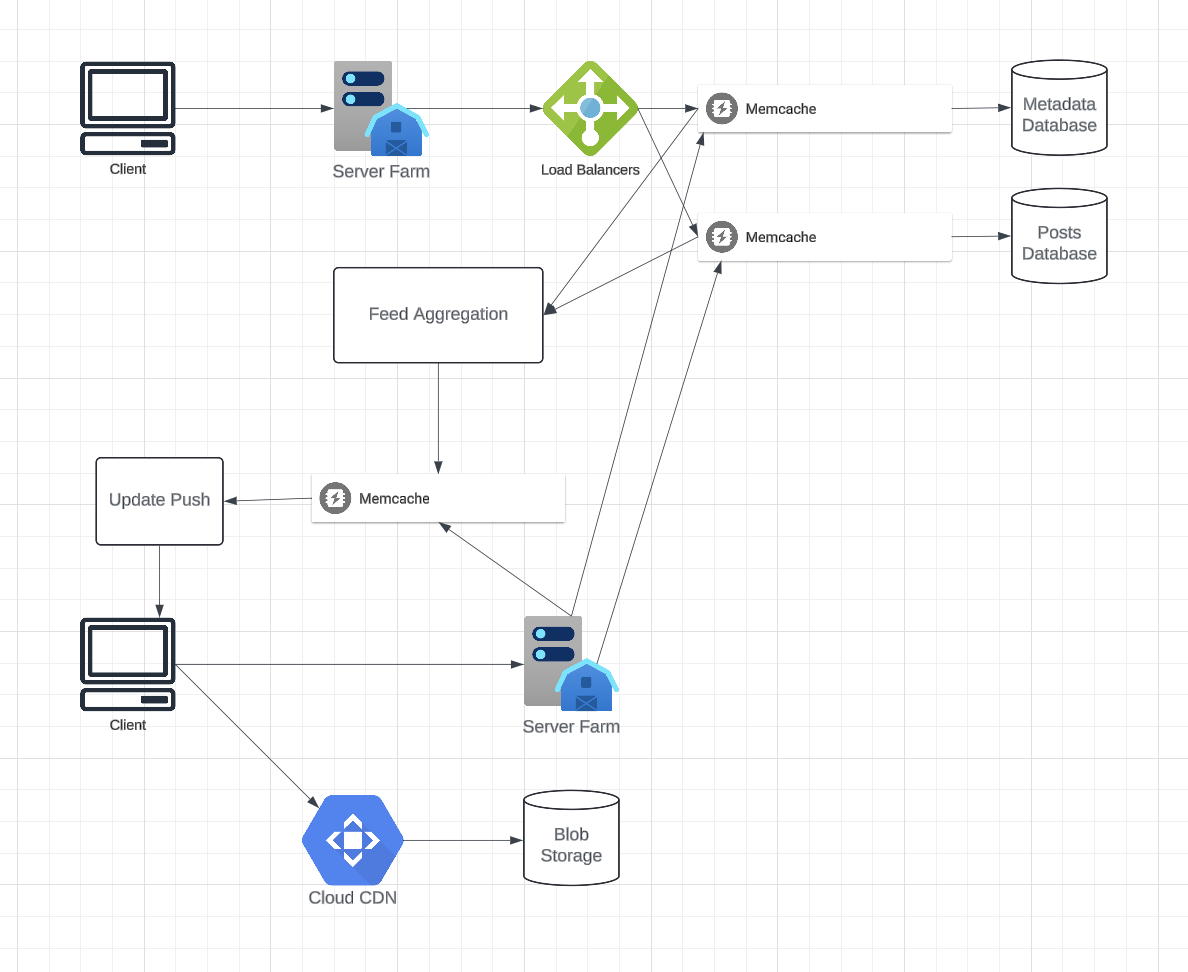
Detailed Component Design
a. Feed Generation
The newsfeed generation service retrieves the most recent and relevant posts from the users and entities that an individual follows. The process involves:
- Identifying all users and entities a user follows.
- Fetching the latest posts from these sources.
- Ranking the posts for relevance and popularity.
- Storing the pre-generated feed in memory to ensure a low-latency experience.
Challenges in Feed Generation:
- High latency for users with many connections due to the large volume of posts.
- Timeline generation occurring only when the user requests the feed, causing delays.
- Live updates generating significant workload, particularly for highly followed users.
- Efficiently handling real-time feed updates without overwhelming the server.
Offline Feed Generation:
- Dedicated servers can pre-generate feeds and store them in memory.
- Periodic updates ensure freshness without on-demand processing.
- Memory management involves using a hash table to store feed items, enabling quick access and updates.
Feed Item Storage Optimization:
- Initially, store 500 feed items per user, adjusting based on usage.
- Use caching strategies like LRU for infrequent users.
b. Feed Publishing
Feed data can be delivered using two main approaches:
- Pull Model (Fan-out-on-load): Users request feed updates manually or at regular intervals. This minimizes server load but may delay new data visibility.
- Push Model (Fan-out-on-write): Updates are pushed to users as they occur, ensuring real-time delivery but increasing server workload.
- Hybrid Approach: Combine push notifications for high-priority updates and pull mechanisms for the rest.
c. Optimizations:
- Limit the number of feed items returned per request (e.g., 20 items).
- Notify users about new posts selectively, reducing bandwidth usage on mobile devices.
9. Feed Ranking
Feed ranking can be enhanced by evaluating various signals such as:
- Engagement metrics: Likes, comments, and shares.
- Content type: Presence of images, videos, or links.
- Time decay: Prioritize recent posts.
- Relevance: Based on user interests and activity patterns.
By refining ranking algorithms, the system can improve user engagement, retention, and revenue.
Data Partitioning
a. Sharding Posts and Metadata: Distribute data across multiple servers to handle high write and read loads efficiently. We can have composite partitioning using [CreationTime, PostID]. This way we can process shards selectively based on recency and distribute load evenly with ID based hashed partitioning.
b. Sharding Feed Data: Partition feed data by UserID, ensuring that each user's feed resides on a single server for quick access. Consistent hashing can facilitate scalability and fault tolerance.
Pagination and Cursor Implementation
Pagination is essential to ensure efficient delivery of feed items to users, especially when the dataset is extensive. By using a cursor-based pagination approach, we can fetch feed items incrementally without overloading the system or the client.
Cursor-based Pagination:
- How it works:
- Each feed item is assigned a unique sequential identifier, such as a timestamp or a numeric ID.
- When fetching feed items, the client includes a cursor in the request. This cursor indicates the position of the last feed item retrieved.
- The server uses this cursor to fetch the next set of items, ensuring that results are consistent and non-overlapping.
- Advantages:
- Efficient for dynamic datasets where feed items are frequently added or updated.
- Avoids issues with data shifting that can occur with offset-based pagination.
- Reduces server-side processing, as only the relevant range of data is queried.
API Example:
GET /getFeed
Headers: { Authorization: Bearer <token> }
Params: {
cursor: <last_fetched_id>,
limit: <number_of_items>
}
Response:
{
"feedItems": [ ... ],
"nextCursor": <new_cursor>
}
Integration into System Design:
- Front-end: The client stores the cursor locally and includes it in subsequent requests for additional feed items.
- Back-end:
- The cursor is processed to determine the starting point for the next query.
- The server ensures that each response includes a new cursor for further pagination.
- Performance: Cursor-based pagination minimizes redundant queries and ensures consistent results, even with frequent updates to the dataset.
Caching with Pagination:
- Frequently accessed feeds can be cached with pagination metadata.
- Subsequent requests with the same cursor can be served from the cache, reducing load on the database.
By implementing cursor-based pagination, the system can efficiently manage large datasets while ensuring a smooth user experience.
